
Understanding your data
Today, we use a multiplication of cloud applications that can be used from anywhere on any device. They increase and facilitate collaboration. Sharing data is now so easy. Buying a cloud application and pushing an organisation’s data in that application is also simple and possible without informing the IT department. In addition, with time the volume of data an organisation manages increased. Some datasets present a certain value for an organisation. They are attractive to threats and could cause reputational damage if publicly disclosed. You must take legal and regulatory requirement into account (think GDPR).
In other words, today’s world is data oriented. The IT department has to change and evolve its posture, from a perimeter security approach to a data-centric approach in order to ensure data security. IT Risk & Security expert Raphaël Dropsy dedicated two tech blog posts to this topic. Here you can read the first one, that focuses on understanding your data.
Phases
The data lifecycle is the sequence of stages that a particular unit of data goes through, from its initial generation or capture to its eventual archival and/or deletion at the end of its useful life. It represents the phases the data goes through, from creation to removal. Data lifecycle has already existed for a long time, but cloud computing brought new challenges.
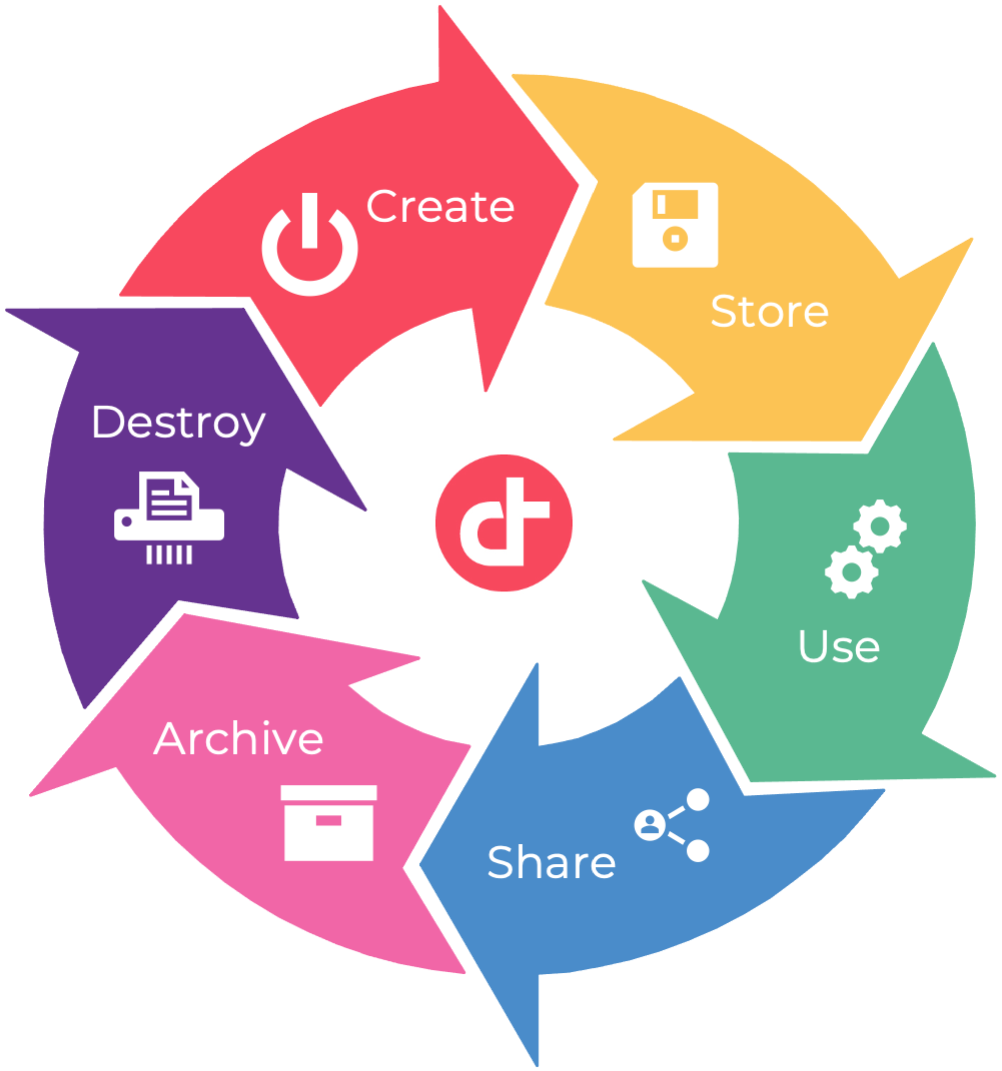
1. CREATE
- Generation or acquisition of new digital content, altering or updating existing content
- Happens on-prem or directly in the cloud
- Preferred time to classify the content according its sensitivity and value to the organisation
2. STORE
- Happens nearly simultaneously with the creation phase
- Consists of committing the data to some sort of storage repository
- Data should be protected in accordance with its classification level
3. USE
- Data is being viewed, processed, used in some sort of activity (modification not included)
- Most vulnerable phase. Data might be transported to unsecure location
4. SHARE
- Data is being made accessible to others. Between users, to customers and partners
- Data is then no longer at the organisation’s control
5. ARCHIVE
- Data leaves active use and enters long term storage
- Data still must be protected according to its classification
- Data might still need to be read in the future. Consideration: cost vs. availability, regulatory and legal requirements
6. DESTROY
- Data is being properly deleted/removed/destroyed. Special consideration according to the type of cloud being used
Understand your data
Secure data implies you understand where it’s located, how it can move between locations, who accesses it and how, what you can do with it and what controls you can deploy.
LOCATION
Data is portable, meaning that it’s capable of moving between different locations. Like inside and outside the enterprise, moved to the cloud for processing, moved to another provider for archiving, and replicated to another zone within a cloud provider’s infrastructure.
ACCESS
Data is accessed from all sorts of different devices which have different security characteristics and may use different applications or clients.
FUNCTION
What can be done with the data by a given actor and a particular location? Like for example creating, copying, transferring files, sharing, updating, using it in a business processing transaction, storing in a file or database.
CONTROL
Controls are used to enforce data protection. A control restricts a list of possible actions to allowed actions. Controls can be preventive, detective or corrective. To determine the necessary controls, you first need to understand the data’s functions, location and access.
From data discovery to data labelling
Remember that not all data present a threat, so it’s important to understand what kind of data you are dealing with. The journey starts with discovering data and ends with labelling it.
1. DISCOVERY
The process of extracting actionable patterns from data, generally performed by humans or, in certain cases, by systems (using content analysis, metadata and labels). Typical issues in this phase come from poor data quality.
2. CATEGORISATION
This is the data owner’s responsibility. He understands how the data is going to be used by the organisation and how to appropriately categorise the data. Examples of categorisation:
- Regulatory compliance: categories based on which regulations apply to a specific dataset (GLBA, PCI-DSS, SOX, HIPAA)
- Business function: specific categories for different uses of data in billing, marketing or operations
- Functional unit: categories for each department or business unit
- Project: categories or datasets categorised by the projects they are associated with
3. DATA CLASSIFICATION
Once again, the data owner is responsible for the classification. It can take any form defined by the organisation and it should be applied uniformly. Examples of classification:
- Sensitivity: data is assigned a classification according to its sensitivity, based on the negative impact an unauthorised disclosure would cause
- Criticality: data that is deemed critical to organisational survival might be classified in a manner distinct from trivial, basic operational data
- Jurisdiction: the geophysical location of the source or storage point of the data might have a significant bearing on how that data is treated and handled (Personally Identifiable Information data gathered from EU citizens is subject to EU privacy laws, which are much stricter than privacy laws in the United States)
4. LABELLING
The label should take whatever form is necessary for it to be enduring, understandable and consistent. Labels should be evident and communicate about the pertinent concepts without necessarily disclosing the data they describe.
Labels might include (depending on the organisation’s needs): data owner, date of creation, date of scheduled destruction/disposal, confidentiality level, handling directions, dissemination/distribution instructions, access limitations, source and applicable regulation.

